Ran across this LTX-2.3 ai2v workflow (voice cloning/talking head) on YouTube. Decided to try it out. The first problem occurred when ComfyUI was saying that some nodes were missing in the workflow, but Manager did not show any missing nodes.
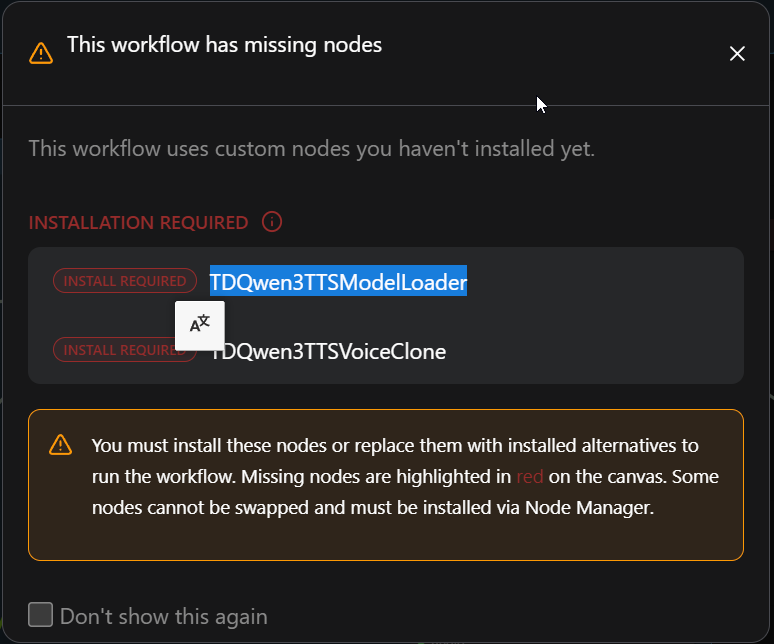
Asked ChatGPT about this. It gave some asinine explanation why Manager was not showing the missing nodes, but did provide a link to where to get them from. Did git clone and then pip install -r requirements.txt for this package. With all nodes in place, tried to run it. No good. Got this error message:

Translated into English:
You must enter a reference text (ref_text), which should contain the actual spoken content from the reference audio. If you cannot provide text, please enable ‘x_vector_only_mode’.

That is, besides the reference audio, it wanted the text of that reference audio in field ref_text. But since this field was disabled in this workflow and I did not feel like figuring out why it was disabled, I just enabled switch x_vector_only_mode.
Ran it again and got an error again, but a different one this time.
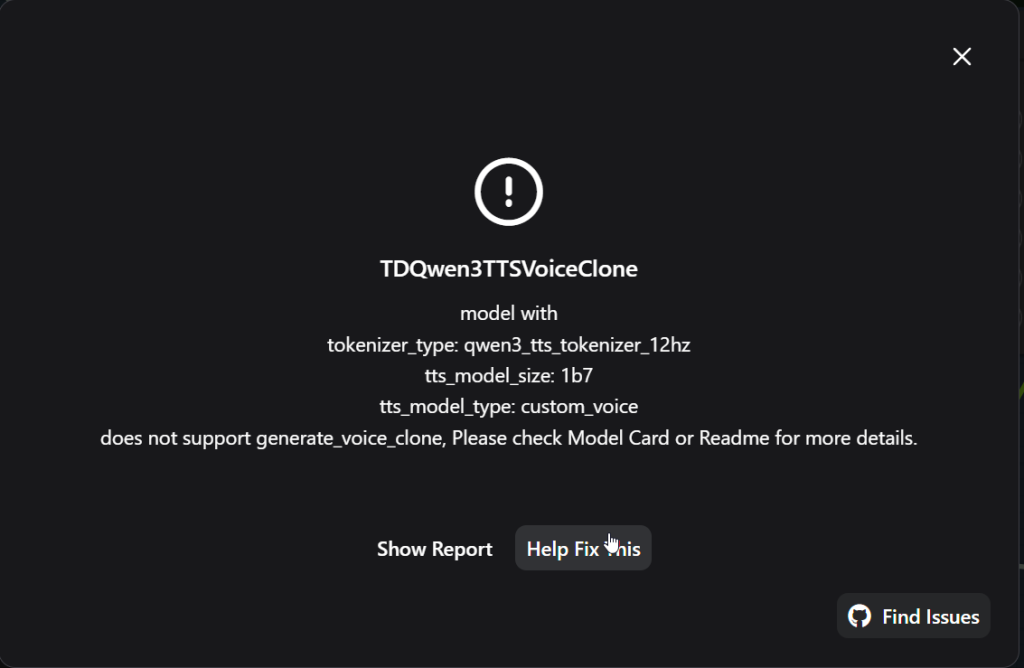
Since this did not tell much, asked ChatGPT again. It said that I had a wrong model here:
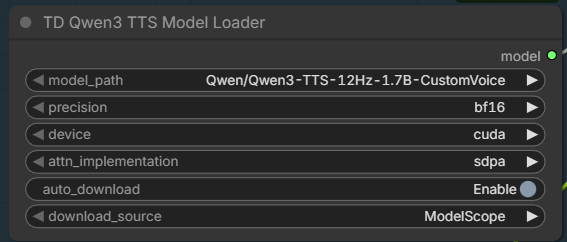
Asked ChatGPT which of the available models should I use:
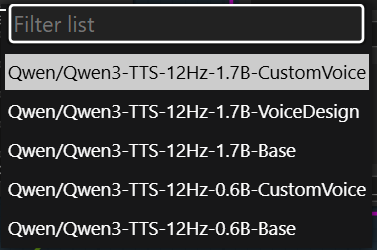
It said to use VoiceDesign.
No problem. Took about 20 minutes to download it, but, unfortunately, it was no good either:
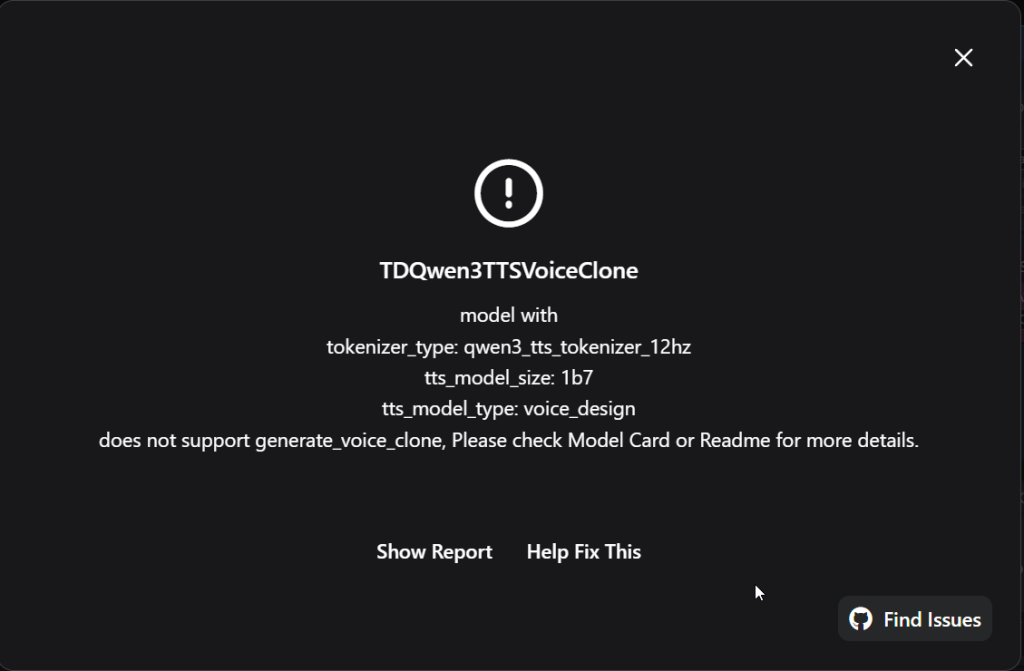
Back to ChatGPT. This time it dumped a shitload of technical gobbledygook, from which I only more of less understood the summary:
“Your current TD Qwen3TTS node stack does not provide voice cloning through TDQwen3TTSVoiceClone, regardless of whether you load CustomVoice or VoiceDesign. “
Whatever that may mean.
So, this is it for the active stage. Back to the drawing board trying to figure out what it needs.